
Learning to Optimize: Where Deep Learning Meets Optimization and Inverse Problems
Mathematical optimization is a fundamental field that seeks to find the minimum of a function over a given set of constraints. Optimization problems are difficult to solve in the presence of non-convexity, combinatorial properties, large sizes, or floating-point numerical challenges. Operations research practitioners, economists, control engineers, and mathematicians have thus spent the last 80 years attempting to master the mathematical and numerical properties of optimization; by doing so, they have discovered a range of methods that work well under favorable properties.
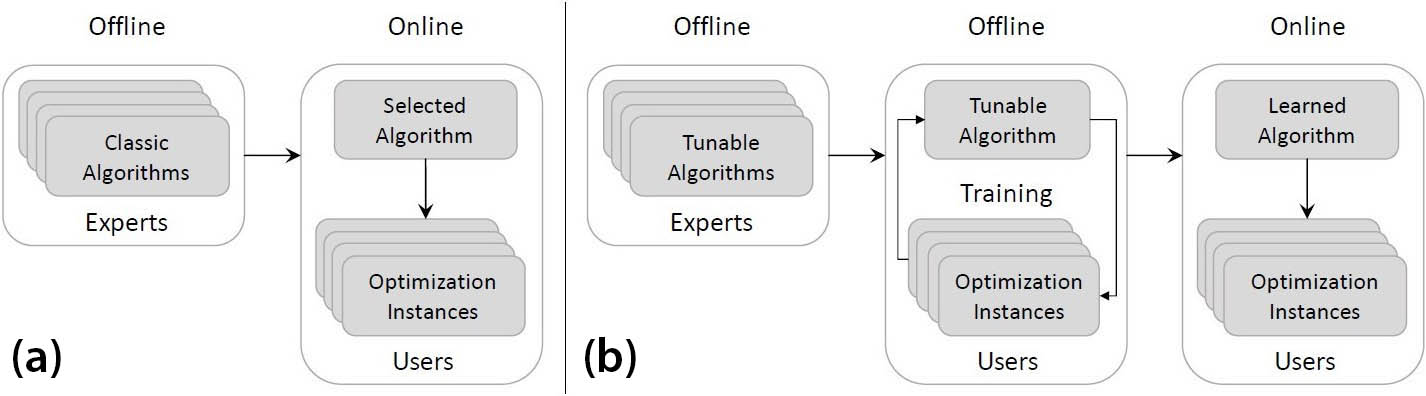
A recent paradigm called “learning to optimize” (L2O) leverages machine learning techniques to accelerate the discovery of new optimization methods (see Figure 1). The 2022 SIAM Conference on Mathematics of Data Science, which took place in San Diego, Calif., this September, featured several presentations about L2O. Wotao Yin (Alibaba Group/Academy for Discovery, Adventure, Momentum and Outlook) delivered an invited presentation that investigated some recent advances in this paradigm, and Daniel McKenzie and Samy Wu Fung (both Colorado School of Mines) also organized a minisymposium session titled “Advances in Learning to Optimize and Optimizing to Learn” that explored this topic through various viewpoints and speakers.
During his plenary talk, Yin sought to unite experts in machine learning and optimization and discover ways to truly outperform existing state-of-the-art technologies. Although it is tempting to simply replace an optimization algorithm with a neural network that is trained to predict minima, this approach does not always stand up to rigorous benchmarking. Yet neural networks still show promise, and recent results from Yin’s group proved that representing (mixed-integer) linear programs as graphs allows proper graph neural networks to accurately predict feasibility, unboundedness, and solutions [2, 3].
Yin also discussed how the use of optimization know-how in conjunction with machine learning can lead to easier learning problems. He demonstrated this point with a series of papers that study the learned iterative shrinkage and thresholding algorithm (LISTA), which reduces the number of trainable parameters from hundreds of thousands to only three [1, 6]. Yin concluded his presentation by expressing his preference for symbolic formulations over deep neural networks.
The minisymposium talks focused on L2O methods that use a class of architectures called implicit networks (also known as deep equilibrium or fixed-point networks). The outputs of implicit networks are given by a fixed point (or optimality) condition, making them natural architectures for L2O models. However, the main challenge associated with implicit networks (and hence implicit L2O models) is their training difficulty. Backpropagation through implicit networks often requires that one solve a large linear system that arises from the implicit function theorem; solving this linear system is therefore the main computational bottleneck when training such networks.
![<strong>Figure 2.</strong> Sample PyTorch code for Jacobian-free backpropagation (JFB). Users can perform backpropagation with standard automatic differentiation tools. Figure adapted from [4].](/media/0rthkk4i/figure2.jpg)
In the first minisymposium address, Fung presented a new technique called Jacobian-free backpropagation (JFB) that avoids the need to solve this Jacobian-based linear system (see Figure 2) [4, 7]. JFB allows users to backpropagate through a network in just four lines of code (in the same manner as automatic differentiation for standard neural networks), thus making implicit L2O networks more accessible to the general scientific community.
Zaccharie Ramzi (ENS Ulm, CNRS) delivered a talk on a complementary approach called SHaring the INverse Estimate (SHINE), which uses a quasi-Newton method for the forward pass. The quasi-Newton matrices from this pass then help to efficiently approximate the inverse Jacobian matrix in the direction that facilitates backpropagation. In conjunction with JFB, SHINE greatly accelerates the training of large-scale deep equilibrium networks [8].
The oldest application of L2O involves mathematical imaging problems like deblurring, super-resolution imaging, and image reconstruction from computed tomography or magnetic resonance imaging (MRI) measurements. Although researchers understand the physics behind the imaging modalities in these scenarios, the resulting ill-conditioned inverse problem renders the reconstructed image extremely sensitive to the noise that inevitably accumulates during the imaging process. During another talk in the session, Rebecca Willett (University of Chicago) highlighted several recent advances in deep learning for such challenging inverse problems. She argued that the incorporation of knowledge of the problem’s underlying physics is crucial when one applies deep learning to imaging. She also encouraged attendees to view the entire reconstruction algorithm as a big neural network and utilize a priori knowledge of the imaging physics to set some of the weights — vastly reducing the number of learned parameters.
![<strong>Figure 3.</strong> An example of a magnetic resonance imaging reconstruction that has undergone 8x acceleration. 3c and 3d were reconstructed with learning to optimize (L2O) approaches and perform best. <strong>3a.</strong> Ground truth. <strong>3b.</strong> Reconstruction with an inverse discrete Fourier transform \((A^\top y)\), where the peak signal-to-noise ratio (PSNR) \(= 24.53\) decibels (dB). <strong>3c.</strong> Reconstruction with deep unrolled proximal gradient descent, where PSNR \(= 31.02\) dB. <strong>3d.</strong> Reconstruction with deep equilibrium proximal gradient descent, where PSNR \(= 32.09\) dB. Figure courtesy of [5].](/media/ljdbyed3/figure3.jpg)
Taking further inspiration from the iterative nature of classical optimization algorithms, Willett’s group has proposed the use of deep equilibrium networks for inverse problems. The team has achieved state-of-the-art performance for MRI reconstruction by combining optimization techniques, an understanding of the underlying physics, and deep learning (see Figure 3). Willett concluded her presentation by noting a number of challenges in this area, particularly regarding efficient training of deep equilibrium networks.
References
[1] Chen, X., Liu, J., Wang, Z., & Yin, W. (2021). Hyperparameter tuning is all you need for LISTA. In Advances in neural information processing systems 34 (NeurIPS 2021) (pp. 11,678-11,689).
[2] Chen, Z., Liu, J., Wang, X., Lu, J., & Yin, W. (2022). On representing linear programs by graph neural networks. Preprint, arXiv:2209.12288.
[3] Chen, Z., Liu, J., Wang, X., Lu, J., & Yin, W. (2022). On representing mixed-integer linear programs by graph neural networks. Preprint, arXiv:2210.10759.
[4] Fung, S.W., Heaton, H., Li, Q., McKenzie, D., Osher, S., & Yin, W. (2022). JFB: Jacobian-free backpropagation for implicit networks. In Proceedings of the thirty-sixth AAAI conference on artificial intelligence (AAAI-22). Association for the Advancement of Artificial Intelligence.
[5] Gilton, D., Ongie, G., & Willett, R. (2021). Deep equilibrium architectures for inverse problems in imaging. IEEE Trans. Comput. Imaging, 7, 1123-1133.
[6] Gregor, K., & LeCun, Y. (2010). Learning fast approximations of sparse coding. In ICML’10: Proceedings of the 27th international conference on machine learning (pp. 399-406). Haifa, Israel: International Machine Learning Society.
[7] Heaton, H., McKenzie, D., Li, Q., Fung, S.W., Osher, S., & Yin, W. (2021). Learn to predict equilibria via fixed point networks. Preprint, arXiv:2106.00906.
[8] Ramzi, Z., Mannel, F., Bai, S., Starck, J.-L., Ciuciu, P., & Moreau, T. (2022). SHINE: SHaring the INverse Estimate from the forward pass for bi-level optimization and implicit models. In ICLR 2022: The tenth international conference on learning representations.
About the Authors
Wotao Yin
Scientist, Alibaba Group/Academy for Discovery, Adventure, Momentum and Outlook
Wotao Yin is a scientist at Alibaba Group/Academy for Discovery, Adventure, Momentum and Outlook, where he directs the Decision Intelligence Lab. He was formerly a professor at the University of California, Los Angeles.

Daniel McKenzie
Assistant Professor, Colorado School of Mines
Daniel McKenzie is an assistant professor in the Department of Applied Mathematics and Statistics at the Colorado School of Mines. He is interested in signal processing, optimization, and machine learning.

Samy Wu Fung
Assistant Professor, Colorado School of Mines
Samy Wu Fung is an assistant professor in the Department of Applied Mathematics and Statistics at the Colorado School of Mines. His research interests include inverse problems, optimization, and deep learning.

Stay Up-to-Date with Email Alerts
Sign up for our monthly newsletter and emails about other topics of your choosing.
